

Welcome to DNNESCAN Finder
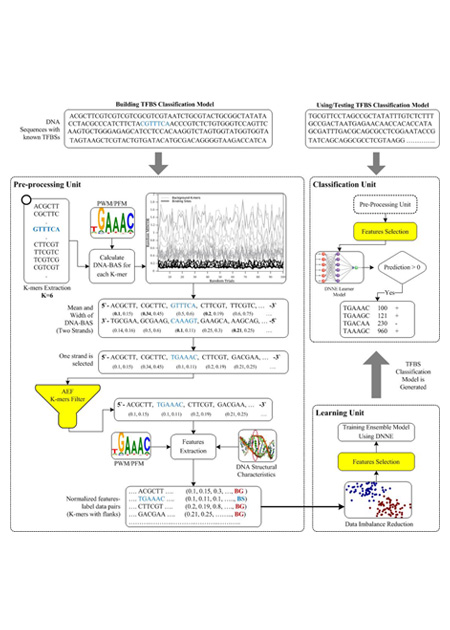
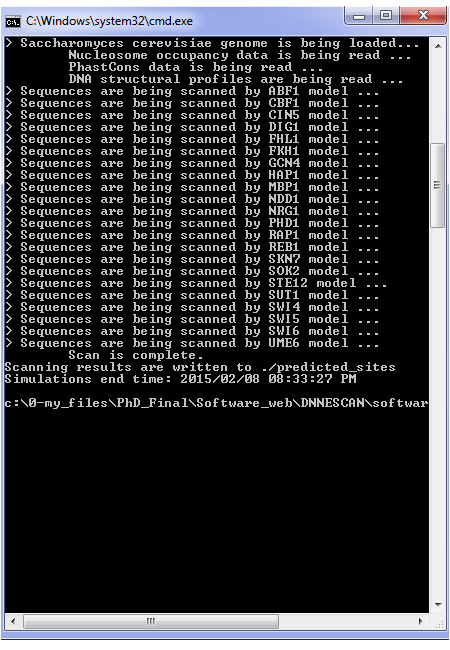
Understanding protein-DNA binding affinity is still a mystery for many transcription factors (TFs). Although several approaches have been proposed in the literature to model the DNA-binding specificity of TFs, they still have some limitations. Most of the methods require a cut-off threshold in order to classify a K-mer as a binding site (BS) and finding such a threshold is usually done by handcraft rather than a science. Some other approaches use a prior knowledge on the biological context of regulatory elements in the genome along with machine learning algorithms to build classifier models for TFBSs. Noticeably, these methods deliberately select the training and testing datasets so that they are very separable. Hence, the current methods do not actually capture the TF-DNA binding relationship. In this paper, we present a threshold-free framework based on a novel ensemble learning algorithm in order to locate TFBSs in DNA sequences. Our proposed approach first creates TF-specific classifier models using data from ChIP-chip experiments and a prior biological knowledge on DNA sequences and TF binding preferences. Systematic background filtering algorithms are utilized to remove non-functional K-mers from training and testing datasets. The highly imbalanced ratio between known binding sites and background K-mers in the training dataset is alleviated using a random oversampling algorithm. To reduce the complexity of classifier models, a fast feature selection algorithm is employed to remove redundant and irrelevant K-mer characteristics. Finally, the created classifier models are used to scan new DNA sequences, identify potential binding sites and answer some biological questions.